编译出错
bash: ./complie.sh:Permission denied/usr/bin/env: ‘bash\r’: No such file or directory- 解决方法如下图所示
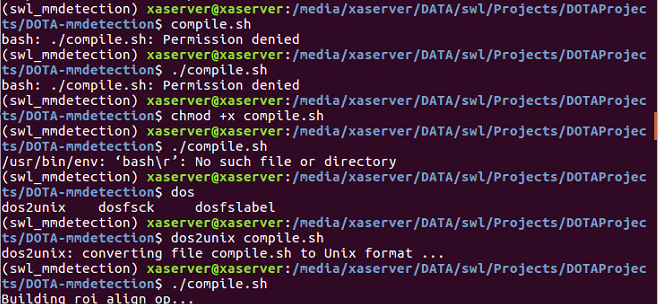
-
同样的操作处理
dist_train.sh如果需要指定使用那一块GPU需要修改dist_train.sh文件为:1 2 3 4 5
#!/usr/bin/env bash PYTHON=${PYTHON:-"python"} CUDA_VISIBLE_DEVICES=0 $PYTHON -m torch.distributed.launch --nproc_per_node=$2 $(dirname "$0")/train.py $1 --launcher pytorch ${@:3}
每次修改Python文件都需要重新编译问题
在安装使用python setup.py develop or pip install -e 来解决。
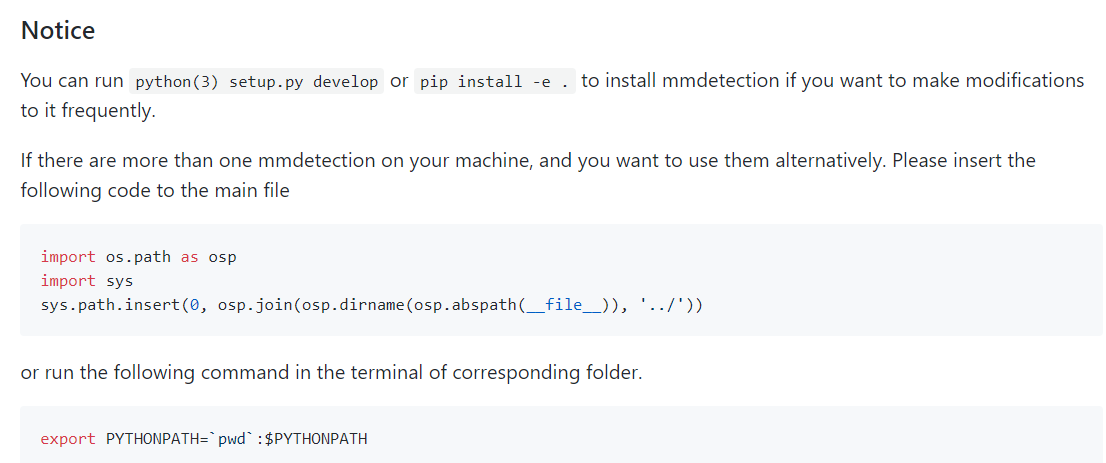
运行 dist_train.sh 文件报 Address already in use错误
原因是一台机子上跑了两个mmdetection代码导致节点冲突,解决办法有两个:
-
修改配置文件中的
dist_params = dict(backend='nccl')为dist_params = dict(backend='nccl', master_port=xxxx)其中 xxxx 是指没有使用的任意端口。 -
修改
dist_params.sh为:1
CUDA_VISIBLE_DEVICES=0 $PYTHON -m torch.distributed.launch --nproc_per_node=$2 --master_port xxxx $(dirname "$0")/train.py $1 --launcher pytorch ${@:3} #其中 xxxx 是指没有使用的任意端口
bug还在挖掘中。。。
代码修改日志
修改预测代码时(2019-4-29)
-
新增文件
demo/demo.py和tools/DOTA_predictor.py两个预测文件,其中demo.py是用来显示demo图片预测的结果,而DOTA_predictor.py主要是用来预测图片. -
修改文件:
-
mmdet/core/evaluation/class_names.py文件.新增函数dota_classes(), 并且修改dataset_aliases如下所示. 这儿修改主要是解决使用mmdet.api中的show_result()函数时类别对应不上的问题(默认是使用Coco数据集)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
def dota_classes(): return ["plane", "baseball-diamond", "bridge", "ground-track-field", "small-vehicle", "large-vehicle", "ship", "tennis-court", "basketball-court", "storage-tank", "soccer-ball-field", "roundabout", "harbor", "swimming-pool", "helicopter"] dataset_aliases = { 'voc': ['voc', 'pascal_voc', 'voc07', 'voc12'], 'imagenet_det': ['det', 'imagenet_det', 'ilsvrc_det'], 'imagenet_vid': ['vid', 'imagenet_vid', 'ilsvrc_vid'], 'coco': ['coco', 'mscoco', 'ms_coco'], 'dota': ['dota','DOTA'] }
- 修改
mmdet/datasets/coco.py和mmdet/datasets/custom.py文件, 使代码能够根据测试代码读取相应的测试数据. 其中custom.py文件中主要修改__init__()函数中的给类的属性赋值的顺序,即把test_mode这个属性的赋值放在读取ann_file(即调用load_annotations()函数)之前.coco.py文件修改load_annotations()函数, 使在读取json文件的时候根据是训练还是测试读取相应的json文件(其中测试的时候读取的json文件只包含图片信息).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89
# TODO custom.py 文件中需要修改的地方(直接复制粘贴替换__init__函数) def __init__(self, ann_file, img_prefix, img_scale, img_norm_cfg, multiscale_mode='value', size_divisor=None, proposal_file=None, num_max_proposals=1000, flip_ratio=0, with_mask=True, with_crowd=True, with_label=True, with_semantic_seg=False, seg_prefix=None, seg_scale_factor=1, extra_aug=None, resize_keep_ratio=True, test_mode=False): # prefix of images path self.img_prefix = img_prefix # (long_edge, short_edge) or [(long1, short1), (long2, short2), ...] self.img_scales = img_scale if isinstance(img_scale, list) else [img_scale] assert mmcv.is_list_of(self.img_scales, tuple) # normalization configs self.img_norm_cfg = img_norm_cfg # multi-scale mode (only applicable for multi-scale training) self.multiscale_mode = multiscale_mode assert multiscale_mode in ['value', 'range'] # max proposals per image self.num_max_proposals = num_max_proposals # flip ratio self.flip_ratio = flip_ratio assert flip_ratio >= 0 and flip_ratio <= 1 # padding border to ensure the image size can be divided by # size_divisor (used for FPN) self.size_divisor = size_divisor # with mask or not (reserved field, takes no effect) self.with_mask = with_mask # some datasets provide bbox annotations as ignore/crowd/difficult, # if `with_crowd` is True, then these info is returned. self.with_crowd = with_crowd # with label is False for RPN self.with_label = with_label # with semantic segmentation (stuff) annotation or not self.with_seg = with_semantic_seg # prefix of semantic segmentation map path self.seg_prefix = seg_prefix # rescale factor for segmentation maps self.seg_scale_factor = seg_scale_factor # in test mode or not self.test_mode = test_mode # load annotations (and proposals) self.img_infos = self.load_annotations(ann_file) if proposal_file is not None: self.proposals = self.load_proposals(proposal_file) else: self.proposals = None # filter images with no annotation during training if not test_mode: valid_inds = self._filter_imgs() self.img_infos = [self.img_infos[i] for i in valid_inds] if self.proposals is not None: self.proposals = [self.proposals[i] for i in valid_inds] # set group flag for the sampler if not self.test_mode: self._set_group_flag() # transforms self.img_transform = ImageTransform( size_divisor=self.size_divisor, **self.img_norm_cfg) self.bbox_transform = BboxTransform() self.mask_transform = MaskTransform() self.seg_transform = SegMapTransform(self.size_divisor) self.numpy2tensor = Numpy2Tensor() # if use extra augmentation if extra_aug is not None: self.extra_aug = ExtraAugmentation(**extra_aug) else: self.extra_aug = None # image rescale if keep ratio self.resize_keep_ratio = resize_keep_ratio
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59
def prepare_test_img(self, idx): """Prepare an image for testing (multi-scale and flipping)""" img_info = self.img_infos[idx] img = mmcv.imread(osp.join(self.img_prefix, img_info['filename'])) if self.proposals is not None: proposal = self.proposals[idx][:self.num_max_proposals] if not (proposal.shape[1] == 4 or proposal.shape[1] == 5): raise AssertionError( 'proposals should have shapes (n, 4) or (n, 5), ' 'but found {}'.format(proposal.shape)) else: proposal = None def prepare_single(img, scale, flip, proposal=None): _img, img_shape, pad_shape, scale_factor = self.img_transform( img, scale, flip, keep_ratio=self.resize_keep_ratio) _img = to_tensor(_img) _img_meta = dict( ori_shape=(img_info['height'], img_info['width'], 3), img_shape=img_shape, pad_shape=pad_shape, scale_factor=scale_factor, flip=flip, img_name=img_info['filename']) # TODO 这儿新增一个属性 if proposal is not None: if proposal.shape[1] == 5: score = proposal[:, 4, None] proposal = proposal[:, :4] else: score = None _proposal = self.bbox_transform(proposal, img_shape, scale_factor, flip) _proposal = np.hstack( [_proposal, score]) if score is not None else _proposal _proposal = to_tensor(_proposal) else: _proposal = None return _img, _img_meta, _proposal imgs = [] img_metas = [] proposals = [] for scale in self.img_scales: _img, _img_meta, _proposal = prepare_single( img, scale, False, proposal) imgs.append(_img) img_metas.append(DC(_img_meta, cpu_only=True)) proposals.append(_proposal) if self.flip_ratio > 0: _img, _img_meta, _proposal = prepare_single( img, scale, True, proposal) imgs.append(_img) img_metas.append(DC(_img_meta, cpu_only=True)) proposals.append(_proposal) data = dict(img=imgs, img_meta=img_metas) if self.proposals is not None: data['proposals'] = proposals return data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
# TODO coco.py 文件中需要修改的地方 def load_annotations(self, ann_file): if not self.test_mode: self.coco = COCO(ann_file) self.cat_ids = self.coco.getCatIds() self.cat2label = { cat_id: i + 1 for i, cat_id in enumerate(self.cat_ids) } self.img_ids = self.coco.getImgIds() img_infos = [] for i in self.img_ids: info = self.coco.loadImgs([i])[0] info['filename'] = info['file_name'] img_infos.append(info) return img_infos else: # 测试 self.coco = COCO(ann_file) self.img_ids = self.coco.getImgIds() img_infos = [] for i in self.img_ids: info = self.coco.loadImgs([i])[0] info['filename'] = info['file_name'] img_infos.append(info) return img_info
- 修改
-
mmdet/models/detectors/base.py和mmdet/datasets/custom.py. 使得可以利用网络自带的预测代码,进行多尺度和翻转预测.其中在custom.py中的prepare_test_img()函数中的内部函数prepare_single()中, 给_img_meta新增了预测图像的名称属性img_name=img_info['filename'](可以在预测的时候知道是哪幅图片). 在base.py文件中新增了一个get_result()函数,其类似于show_result()函数,只是最后不是显示图像而是把bboxes和labels返回.新增函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
def get_result(self, data, result, img_norm_cfg, dataset='coco', score_thr=0.3): if isinstance(result, tuple): bbox_result, segm_result = result else: bbox_result, segm_result = result, None img_tensor = data['img'][0] img_metas = data['img_meta'][0].data[0] imgs = tensor2imgs(img_tensor, **img_norm_cfg) assert len(imgs) == len(img_metas) if isinstance(dataset, str): class_names = get_classes(dataset) elif isinstance(dataset, (list, tuple)) or dataset is None: class_names = dataset else: raise TypeError( 'dataset must be a valid dataset name or a sequence' ' of class names, not {}'.format(type(dataset))) for img, img_meta in zip(imgs, img_metas): h, w, _ = img_meta['img_shape'] img_show = img[:h, :w, :] bboxes = np.vstack(bbox_result) # draw segmentation masks if segm_result is not None: segms = mmcv.concat_list(segm_result) inds = np.where(bboxes[:, -1] > score_thr)[0] for i in inds: color_mask = np.random.randint( 0, 256, (1, 3), dtype=np.uint8) mask = maskUtils.decode(segms[i]).astype(np.bool) img_show[mask] = img_show[mask] * 0.5 + color_mask * 0.5 # draw bounding boxes labels = [ np.full(bbox.shape[0], i, dtype=np.int32) for i, bbox in enumerate(bbox_result) ] labels = np.concatenate(labels) # TODO 新增设置阈值的代码 inds = np.where(bboxes[:, -1] > score_thr)[0] bboxes = bboxes[inds] labels = labels[inds] return bboxes, labels
tools/DOTA_predictor.py文件是对原来的test.py文件的修改.主要修改了两个函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
def single_test(model, data_loader, show=False, output_dir=None): model.eval() results = [] dataset = data_loader.dataset CLASSES = dataset.CLASSES if output_dir is not None: if not os.path.exists(output_dir): os.makedirs(output_dir) for i in os.listdir(output_dir): if i.endswith('.txt'): os.remove(os.path.join(output_dir, i)) prog_bar = mmcv.ProgressBar(len(dataset)) for i, data in enumerate(data_loader): with torch.no_grad(): result = model(return_loss=False, rescale=not show, **data) results.append(result) if show: model.module.show_result(data, result, dataset.img_norm_cfg, dataset=dataset.CLASSES) if output_dir is not None: img_name = data['img_meta'][0].data[0][0]['img_name'] bboxes,labels = model.module.get_result(data, result, dataset.img_norm_cfg, dataset=dataset.CLASSES) for bbox,label in zip(bboxes,labels): lab = CLASSES[label] f = open(os.path.join(output_dir,'Task2_' + lab + '.txt'),'a') f.write('{} {} {} {} {} {} \n'.format(img_name, float(bbox[4]), int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3]))) batch_size = data['img'][0].size(0) for _ in range(batch_size): prog_bar.update() return results
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
def main(): args = parse_args() cfg = mmcv.Config.fromfile(args.config) # set cudnn_benchmark if cfg.get('cudnn_benchmark', False): torch.backends.cudnn.benchmark = True cfg.model.pretrained = None cfg.data.test.test_mode = True dataset = obj_from_dict(cfg.data.test, datasets, dict(test_mode=True)) if args.gpus == 1: model = build_detector( cfg.model, train_cfg=None, test_cfg=cfg.test_cfg) load_checkpoint(model, args.checkpoint) model = MMDataParallel(model, device_ids=[0]) data_loader = build_dataloader( dataset, imgs_per_gpu=1, workers_per_gpu=cfg.data.workers_per_gpu, num_gpus=1, dist=False, shuffle=False) outputs = single_test(model, data_loader, args.show, args.out) else: model_args = cfg.model.copy() model_args.update(train_cfg=None, test_cfg=cfg.test_cfg) model_type = getattr(detectors, model_args.pop('type')) outputs = parallel_test( model_type, model_args, args.checkpoint, dataset, _data_func, range(args.gpus), workers_per_gpu=args.proc_per_gpu)
-
-
解决在计算
IoU时出现Out of memory的问题(2019-6-12)修改代码文件
mmdet/core/assigners/max_iou_assigners.py中的assign()函数.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
if bboxes.shape[0] == 0 or gt_bboxes.shape[0] == 0: raise ValueError('No gt or bboxes') USE_CPU_MODE = True N = gt_bboxes.shape[0] if USE_CPU_MODE and N>100: bboxes = bboxes[:, :4] bboxes = bboxes.cpu() gt_bboxes = gt_bboxes.cpu() if gt_bboxes_ignore is not None: gt_bboxes_ignore = gt_bboxes_ignore.cpu() if gt_labels is not None: gt_labels = gt_labels.cpu() overlaps = bbox_overlaps(gt_bboxes, bboxes) if (self.ignore_iof_thr > 0) and (gt_bboxes_ignore is not None) and ( gt_bboxes_ignore.numel() > 0): if self.ignore_wrt_candidates: ignore_overlaps = bbox_overlaps( bboxes, gt_bboxes_ignore, mode='iof') ignore_max_overlaps, _ = ignore_overlaps.max(dim=1) else: ignore_overlaps = bbox_overlaps( gt_bboxes_ignore, bboxes, mode='iof') ignore_max_overlaps, _ = ignore_overlaps.max(dim=0) overlaps[:, ignore_max_overlaps > self.ignore_iof_thr] = -1 assign_result = self.assign_wrt_overlaps(overlaps, gt_labels) assign_result.gt_inds = assign_result.gt_inds.cuda() assign_result.max_overlaps = assign_result.max_overlaps.cuda() if assign_result.labels is not None: assign_result.labels = assign_result.labels.cuda() else: bboxes = bboxes[:, :4] overlaps = bbox_overlaps(gt_bboxes, bboxes) if (self.ignore_iof_thr > 0) and (gt_bboxes_ignore is not None) and ( gt_bboxes_ignore.numel() > 0): if self.ignore_wrt_candidates: ignore_overlaps = bbox_overlaps( bboxes, gt_bboxes_ignore, mode='iof') ignore_max_overlaps, _ = ignore_overlaps.max(dim=1) else: ignore_overlaps = bbox_overlaps( gt_bboxes_ignore, bboxes, mode='iof') ignore_max_overlaps, _ = ignore_overlaps.max(dim=0) overlaps[:, ignore_max_overlaps > self.ignore_iof_thr] = -1 assign_result = self.assign_wrt_overlaps(overlaps, gt_labels) return assign_result
-
新增使用
mask做旋转框的预测代码. 修改代码mmdet/models/detectors/base.py文件中新增下面两个函数。在tools中新增DOTA_obb_predictor.py文件。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129
def show_obb_result(self, data, result, img_norm_cfg, dataset=None, score_thr=0.3): if isinstance(result, tuple): bbox_result, segm_result = result else: bbox_result, segm_result = result, None img_tensor = data['img'][0] img_metas = data['img_meta'][0].data[0] imgs = tensor2imgs(img_tensor, **img_norm_cfg) assert len(imgs) == len(img_metas) if dataset is None: class_names = self.CLASSES elif isinstance(dataset, str): class_names = get_classes(dataset) elif isinstance(dataset, (list, tuple)): class_names = dataset else: raise TypeError( 'dataset must be a valid dataset name or a sequence' ' of class names, not {}'.format(type(dataset))) for img, img_meta in zip(imgs, img_metas): h, w, _ = img_meta['img_shape'] img_show = img[:h, :w, :] bboxes = np.vstack(bbox_result) labels = [np.full(bbox.shape[0], i, dtype=np.int32) for i, bbox in enumerate(bbox_result)] labels = np.concatenate(labels) # draw segmentation masks if segm_result is not None: segms = mmcv.concat_list(segm_result) inds = np.where(bboxes[:, -1] > score_thr)[0] for i in inds: color_mask = np.random.randint( 0, 256, (3), dtype=np.uint8).tolist() mask = maskUtils.decode(segms[i]).astype(np.uint8) contours, hierarchy = cv2.findContours( mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE ) if len(contours) == 0: continue rect = cv2.minAreaRect(contours[0]) box = cv2.boxPoints(rect) pt = [] pt.append(tuple([box[0][0],box[0][1]])) pt.append(tuple([box[1][0],box[1][1]])) pt.append(tuple([box[2][0],box[2][1]])) pt.append(tuple([box[3][0],box[3][1]])) for j in range(4): cv2.line(img_show, pt[j], pt[(j + 1) % 4], color=color_mask, thickness=2) cv2.putText(img_show,class_names[labels[i]]+"|%.2f"% bboxes[i,-1],(box[0][0],box[0][1]),cv2.FONT_HERSHEY_SIMPLEX ,0.5,(0,255,0)) # img_show = cv2.drawContours(img_show, contours, -1, color_mask, 3) cv2.imshow("img",img_show) cv2.waitKey(0) def get_obb_result(self, data, result, img_norm_cfg, dataset='coco', score_thr=0.3): if isinstance(result, tuple): bbox_result, segm_result = result else: bbox_result, segm_result = result, None img_tensor = data['img'][0] img_metas = data['img_meta'][0].data[0] imgs = tensor2imgs(img_tensor, **img_norm_cfg) assert len(imgs) == len(img_metas) if isinstance(dataset, str): class_names = get_classes(dataset) elif isinstance(dataset, (list, tuple)) or dataset is None: class_names = dataset else: raise TypeError( 'dataset must be a valid dataset name or a sequence' ' of class names, not {}'.format(type(dataset))) for img, img_meta in zip(imgs, img_metas): h, w, _ = img_meta['img_shape'] img_show = img[:h, :w, :] bboxes = np.vstack(bbox_result) bboxes_obb = [] final_inds = [] # draw segmentation masks if segm_result is not None: segms = mmcv.concat_list(segm_result) inds = np.where(bboxes[:, -1] > score_thr)[0] for i in inds: color_mask = np.random.randint( 0, 256, (3), dtype=np.uint8).tolist() mask = maskUtils.decode(segms[i]).astype(np.uint8) import cv2 contours, hierarchy = cv2.findContours( mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE ) if len(contours) == 0: continue rect = cv2.minAreaRect(contours[0]) box = cv2.boxPoints(rect) bboxes_obb.append([box[0][0],box[0][1], box[1][0],box[1][1], box[2][0],box[2][1], box[3][0],box[3][1]]) final_inds.append(i) labels = [ np.full(bbox.shape[0], i, dtype=np.int32) for i, bbox in enumerate(bbox_result) ] labels = np.concatenate(labels) # inds = np.where(bboxes[:, -1] > score_thr)[0] bboxes = bboxes[final_inds] labels = labels[final_inds] bboxes_obb = np.array(bboxes_obb) # 这儿只是坐标,得分取 bboxes 中的得分 return bboxes, labels, bboxes_obb
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128
# DOTA_obb_predictor.py 文件。 import argparse import os import torch import mmcv from mmcv.runner import load_checkpoint, parallel_test, obj_from_dict from mmcv.parallel import scatter, collate, MMDataParallel from mmdet import datasets from mmdet.core import results2json, coco_eval from mmdet.datasets import build_dataloader from mmdet.models import build_detector, detectors def single_test(model, data_loader, show=False, output_dir=None): model.eval() results = [] dataset = data_loader.dataset CLASSES = dataset.CLASSES if output_dir is not None: if not os.path.exists(output_dir): os.makedirs(output_dir) for i in os.listdir(output_dir): if i.endswith('.txt'): os.remove(os.path.join(output_dir, i)) prog_bar = mmcv.ProgressBar(len(dataset)) for i, data in enumerate(data_loader): with torch.no_grad(): result = model(return_loss=False, rescale=not show, **data) results.append(result) if show: model.module.show_obb_result(data, result, dataset.img_norm_cfg, dataset=dataset.CLASSES) if output_dir is not None: img_name = data['img_meta'][0].data[0][0]['img_name'] bboxes, labels, bboxes_obb = model.module.get_obb_result(data, result, dataset.img_norm_cfg, dataset=dataset.CLASSES) for bbox, bbox_obb label in zip(bboxes,bboxes_obb,labels): lab = CLASSES[label] f = open(os.path.join(output_dir,'Task1_' + lab + '.txt'),'a') f.write('{} {} {} {} {} {} {} {} {} {}\n'.format(img_name, float(bbox[4]), int(bbox_obb[0]), int(bbox_obb[1]), int(bbox_obb[2]), int(bbox_obb[3]), int(bbox_obb[4]), int(bbox_obb[5]), int(bbox_obb[6]), int(bbox_obb[7]))) batch_size = data['img'][0].size(0) for _ in range(batch_size): prog_bar.update() return results def _data_func(data, device_id): data = scatter(collate([data], samples_per_gpu=1), [device_id])[0] return dict(return_loss=False, rescale=True, **data) def parse_args(): parser = argparse.ArgumentParser(description='MMDet test detector') parser.add_argument('config', help='test config file path') parser.add_argument('checkpoint', help='checkpoint file') parser.add_argument( '--gpus', default=1, type=int, help='GPU number used for testing') parser.add_argument( '--proc_per_gpu', default=1, type=int, help='Number of processes per GPU') parser.add_argument('--out', help='output result file') parser.add_argument( '--eval', type=str, nargs='+', choices=['proposal', 'proposal_fast', 'bbox', 'segm', 'keypoints'], help='eval types') parser.add_argument('--show', action='store_true', help='show results') args = parser.parse_args() return args def main(): args = parse_args() cfg = mmcv.Config.fromfile(args.config) # set cudnn_benchmark if cfg.get('cudnn_benchmark', False): torch.backends.cudnn.benchmark = True cfg.model.pretrained = None cfg.data.test.test_mode = True dataset = obj_from_dict(cfg.data.test, datasets, dict(test_mode=True)) if args.gpus == 1: model = build_detector( cfg.model, train_cfg=None, test_cfg=cfg.test_cfg) load_checkpoint(model, args.checkpoint) model = MMDataParallel(model, device_ids=[0]) data_loader = build_dataloader( dataset, imgs_per_gpu=1, workers_per_gpu=cfg.data.workers_per_gpu, num_gpus=1, dist=False, shuffle=False) outputs = single_test(model, data_loader, args.show, args.out) else: model_args = cfg.model.copy() model_args.update(train_cfg=None, test_cfg=cfg.test_cfg) model_type = getattr(detectors, model_args.pop('type')) outputs = parallel_test( model_type, model_args, args.checkpoint, dataset, _data_func, range(args.gpus), workers_per_gpu=args.proc_per_gpu) if __name__ == '__main__': main()
-
Previous
论文笔记:FCOS: Fully Convolutational One-Stage Object Detection -
Next
论文笔记:DenseBox:Unifying Landmark Localization with End to End Object Detection