DenseBox主要贡献
- 使用全卷积网络,将检测任务以类似于语义分割的方式处理。实现了端到端的训练和识别,而R-CNN系列算法是从Faster R-CNN中使用了RPN代替了Selective Search才开始实现端到端训练的,而和语义分割的结合更是等到了2017年的Mask R-CNN才开始。
- 多尺度特征,R-CNN系列是从FPN才开始多吃富特征融合的。
- 结合关键点的多任务系统。结合关键点可以进一步提升检测的精度。
DenseBox 概述
训练标签生成
DenseBox没有使用整张图像作为输入进行训练(一张图片上的背景太多,计算时间会严重浪费掉在对没有用的背景的卷积上)。而且使用扭曲或者裁剪将不同比例的图像压缩到相同尺寸会造成信息的丢失。作者提出的策略是从训练图片中裁剪出包含人脸的patch,这些patch包含的背景区域足够完成模型的训练。具体操作如下:
-
根据gt 从训练数据集中裁剪出大小是人脸区域的高的4.8倍的正方形作为一个patch,且使得人脸在这个patch的中心。
-
将这个patch resize到240$\times$240大小。
栗子: 一张训练图片中包含一个60$\times$80人脸,那么第一步会裁剪出大小为384$\times$384的一个patch。在第二步中将这个patch resize到240$\times$240大小。作为训练图像的输入。
通过上面方法得到的patch是正patch,除了这些正patch,DenseBox还随机采样等数量的随机 patch。同时使用翻转,位移和尺度变换三种数据增强的方法产生样本以增强模型的泛化能力。训练集的标签是一个$60\times 60\times 5$的热图,$60\times 60$ 表示热图的尺寸,5表示热图的通道数。

- 图中最前的热图用于标注人脸区域置信度,前景为1,背景为0。DenseBox中没有使用左图中的矩形区域,而是以半径$r_c$为 gt 的高的0.3倍的圆作为标签值,而圆形的中心就是热图的中心,即右图中白色区域。
- 图中后面的四个特征图分别表示像素点到最近的gt的四个边界的距离,如下图所示,其中gt为蓝色矩形,表示为$d=(d_{x^t}^,d_{x^b}^,d_{y^t}^,d_{y^b}^)$,绿色为预测矩形,表示为$\hat{d}=\left(\hat{d}{x^{t}}, \hat{d}{x^{b}}, \hat{d}{y^{k}}, \hat{d}{y^{b}}\right)$。如果训练样本中人的脸比较密集,一个patch中可能出现多个人脸,如果某个人脸和中心点处的人脸的高的比例在[0.8,1.25]之间,则认为改样本为正样本。

网络结构
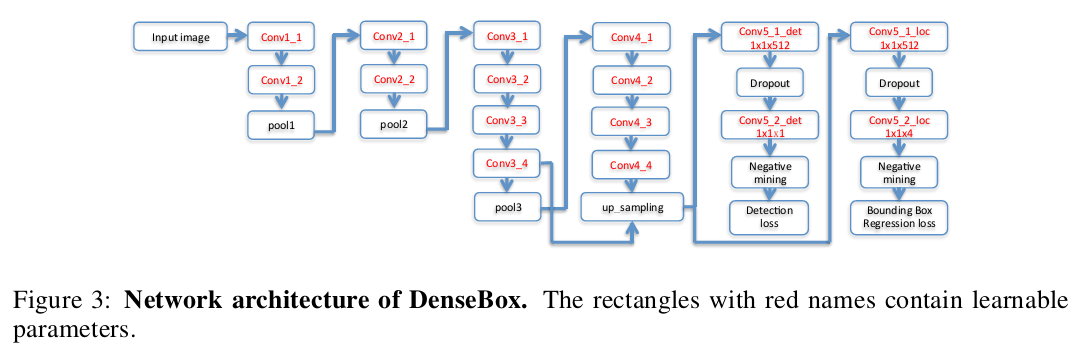
DenseBox 使用16层的VGG19作为backbone,但只使用前12层。后面接了4个$1\times1$的卷积层,其中前两个的最后一层输出类别的得分图,后两个的最后层用来回归边界框。需要注意的是在网络的Conv3_4和Conv4_4之间发生了一次特征融合,融合的方式是Conv4_4经过双线性差值上采样得到与Conv3_4相同分辨率的特征图。通过计算我们可以得知Conv3_4层的感受野的尺寸是 $48\times48 $,该层的尺寸和标签中的人脸尺寸接近,用于捕捉人脸区域的关键特征;Conv4_4层的感受野的大小是 $118\times118$,用于捕捉人脸的上下文特征。网络出了前12层使用VGG19在ImageNet上的预训练权重外,其余的层使用Xavier进行初始化。
多任务训练
DenseBox 网络中有两个损失,第一个是分类损失,第二个是边界框回归损失。分类损失使用$L_2$ loss,形式(1)所示,边界框回归损失如(2)所示: \(\mathcal{L}_{c l s}\left(\hat{y}, y^{*}\right)=\left\|\hat{y}-y^{*}\right\|^{2}\)
\[\mathcal{L}_{l o c}\left(\hat{d}, d^{*}\right)=\sum_{i \in\{t x, t y, b x, b y\}}\left\|\hat{d}_{i}-d_{i}^{*}\right\|^{2}\]平衡采样
1. 忽略灰色区域
所谓灰色区域,是指正负样本边界部分的像素点,因为在这些区域由于标注的样本是很难区分的,让其参加训练反而会降低模型的精度,因此这一部分不参与训练,在论文中,长度小于2的边界部分视为灰色区域。DenseBox使用$f_{ign}$对灰色样本标注,其中$f_{ign}=1$表示灰色区域样本。
2. Hard Negative Mining
DenseBox使用的Hard Negative Mining的策略和SVM类似,具体策略是:
- 计算整个patch的所有样本点,并根据loss进行排序。
- 去其中的1%作为hard-Negative 样本
- 所有的negative样本,一半是采样自hard-negative样本,剩下的一半是从non-hard negative中随机选取。
- 随机采样与negative一样数量的正样本
使用上面操作的得到的正负样本进行训练。
3. 使用掩码的损失函数
\[M\left(\hat{t}_{i}\right)=\left\{\begin{array}{ll}{0} & {f_{i g n}^{i}=1 \text { or } f_{\text {sel}}^{i}=0} \\ {1} & {\text { otherwise }}\end{array}\right.\]\(\mathcal{L}_{d e t}(\theta)=\sum_{i}\left(M\left(\hat{t}_{i}\right) \mathcal{L}_{c l s}\left(\hat{y}_{i}, y_{i}^{*}\right)+\lambda_{\operatorname{loc}}\left[y_{i}^{*}>0\right] M\left(\hat{t}_{i}\right) \mathcal{L}_{l o c}\left(\hat{d}_{i}, d_{i}^{*}\right)\right)\) 其中$\lambda_{loc}$ 是平衡两个任务的参数,论文中值为3。位置$d_i$使用的是归一化的值。
结合关键点检测的多任务模型
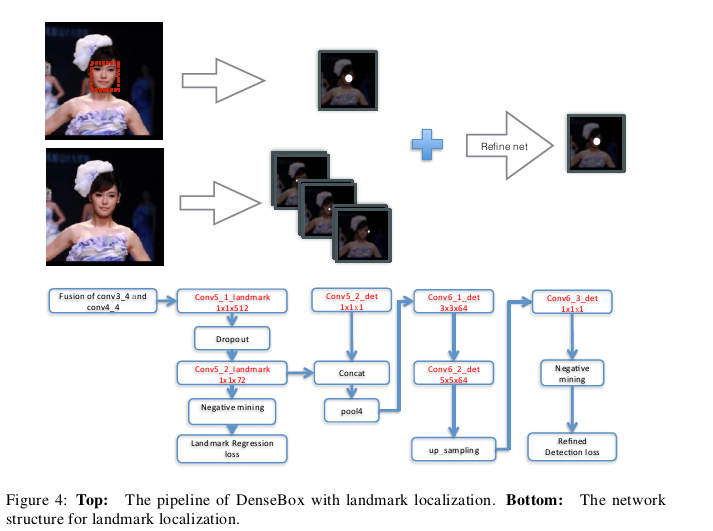
论文中指出当DenseBox加入关键点检测的任务分支时模型的精度会进一步提升,这时只需要在图3的conv3_4和conv4_4融合之后的结果上添加一个用于关键点检测的分支即可,分支的详细结构如图所示。
未详细看。。。。
检测
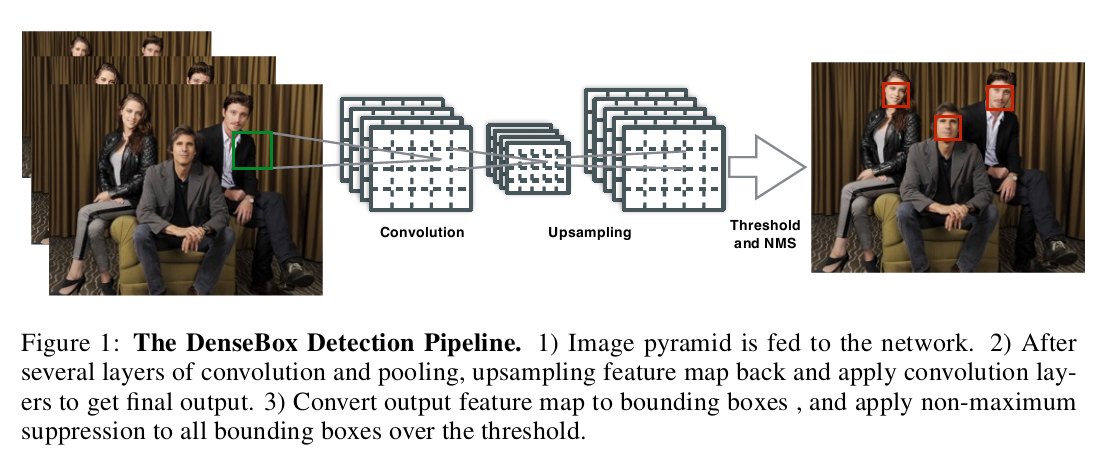
DenseBox的检测流程:
- 图像金字塔输入
- 经过网络后产生5个通道的Feature Map
- 两次双线性插值上采样得到和输入图像相同尺寸的特征图
- 根据特征图得到检测框
- NMS合并检测框得到最终的检测结果
总结
DenseBox在今天看来技术性依旧非常强,虽然作为一个人脸检测的论文被发表,但是其思想也可以迁移到通用的物体检测中。而且得到的效果几乎和Faster R-CNN旗鼓相当。由于采用了FCN的架构,DenseBox本身的速度应该不会太慢,唯一的性能瓶颈应该是图像金字塔的引入。在之后的研究中,DenseBox通过SPP-Net中的金字塔池化的方式将检测时间优化到了GPU的实时。本来DenseBox在物体检测中能有更大的价值的,但是由于其仅限于百度内部使用,并没有开源,论文投稿也比较晚造成了R-CNN系列的一统天下。当然R-CNN系列凭借其代码的规范性,算法的通用性等优点一统天下也不意外。
-
Previous
mmdetection 框架中踩过的坑(DOTA 数据集) -
Next
论文笔记:Cascade R-CNN:Delving into High Quality Object Detection